
[toc]
0x01 Flink特点
- 支持Scala和Java API
- 支持批流一体
- 同时支持高吞吐、低延迟和高性能
- 支持事件时间和处理时间语义,基于事件时间语义能够针对无序事件提供精确、一致的结果,基于处理时间语义能够用在具有极低延迟需求的应用中
- 支持不同时间语义下的窗口调整
- 支持有状态计算
- 支持具有Backpressure功能的持续流模型
- 提供精确一次的状态一致性保障
- Flink在JVM内部实现了自己的内存管理
- 基于轻量的分布式快照CheckPoint的容错
- 支持savePoint机制,手工触发,适用于升级
- 支持高可用配置,与k8s紧密集成
- 提供常见存储系统的连接器,Kafka、ES等
- 提供详细、可只有定制的系统以及应用指标集合,用于提前定位和响应问题

1.1与其他框架对比
| Flink | Spark | Storm | Storm-Trident | |
|---|---|---|---|---|
| 处理模型 | Native | Micro-Batch | Native | Micro-Batch |
| 处理语义 | Exactly-Once | Exactly-Once | At-Least-Once | Exactly-Once |
| 容错 | CheckPoint | CheckPoint | Ack | Ack |
| 吞吐量 | High | High | Low | Medium |
| 延迟 | Low | High | High | verylow |
1.2 处理无界和有界数据
任何类型的数据都可以形成一种事件流。信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。
数据可以被作为 无界 或者 有界 流来处理。
无界流(unbounded stream) 有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
有界流(bounded stream) 有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理
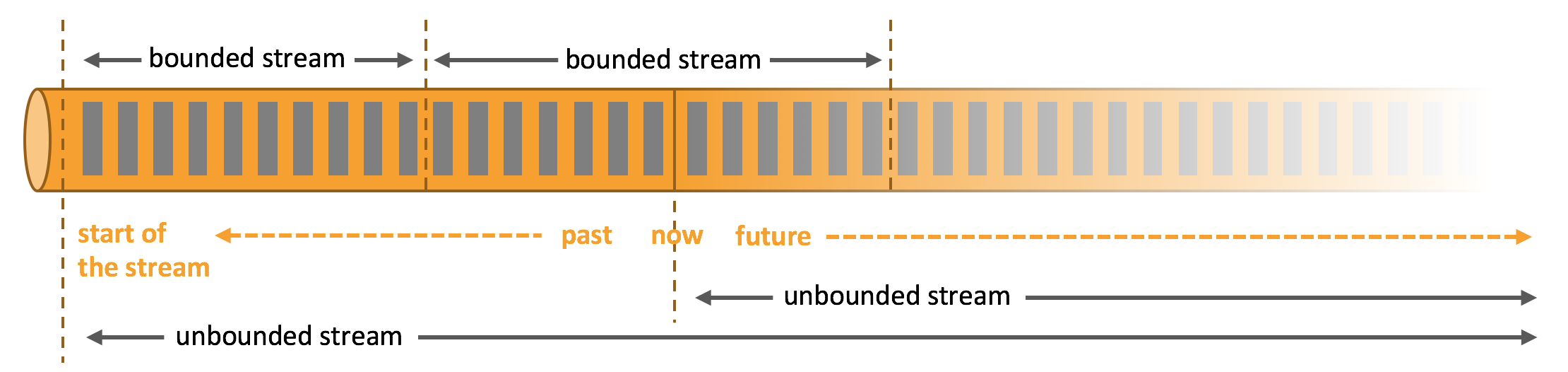
Apache Flink 擅长处理无界和有界数据集 精确的时间控制和状态化使得 Flink 的运行时(runtime)能够运行任何处理无界流的应用。有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。
1.3 状态
只有在每一个单独的事件上进行转换操作的应用才不需要状态,换言之,每一个具有一定复杂度的流处理应用都是有状态的。任何运行基本业务逻辑的流处理应用都需要在一定时间内存储所接收的事件或中间结果,以供后续的某个时间点(例如收到下一个事件或者经过一段特定时间)进行访问并进行后续处理。
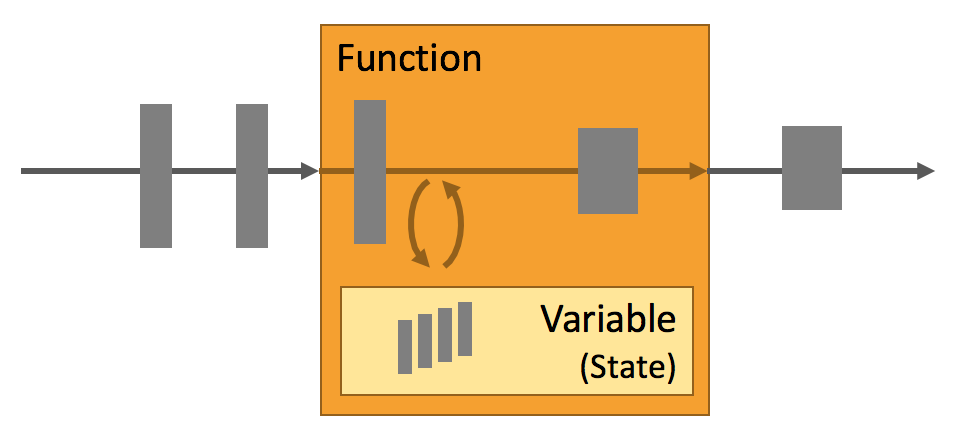
应用状态是 Flink 中的一等公民,Flink 提供了许多状态管理相关的特性支持,其中包括:
多种状态基础类型:Flink 为多种不同的数据结构提供了相对应的状态基础类型,例如原子值(value),列表(list)以及映射(map)。开发者可以基于处理函数对状态的访问方式,选择最高效、最适合的状态基础类型。
插件化的State Backend:State Backend 负责管理应用程序状态,并在需要的时候进行 checkpoint。Flink 支持多种 state backend,可以将状态存在内存或者 RocksDB。RocksDB 是一种高效的嵌入式、持久化键值存储引擎。Flink 也支持插件式的自定义 state backend 进行状态存储。
精确一次语义:Flink 的 checkpoint 和故障恢复算法保证了故障发生后应用状态的一致性。因此,Flink 能够在应用程序发生故障时,对应用程序透明,不造成正确性的影响。超大数据量状态:Flink 能够利用其异步以及增量式的 checkpoint 算法,存储数 TB 级别的应用状态。
可弹性伸缩的应用:Flink 能够通过在更多或更少的工作节点上对状态进行重新分布,支持有状态应用的分布式的横向伸缩
1.4 稳定运行
在分布式系统中,服务故障是常有的事,为了保证服务能够7*24小时稳定运行,像Flink这样的流处理器故障恢复机制是必须要有的。显然这就意味着,它(这类流处理器)不仅要能在服务出现故障时候能够重启服务,而且还要当故障发生时,保证能够持久化服务内部各个组件的当前状态,只有这样才能保证在故障恢复时候,服务能够继续正常运行,好像故障就没有发生过一样。
Flink通过几下多种机制维护应用可持续运行及其一致性:
- 检查点的一致性: Flink的故障恢复机制是通过建立分布式应用服务状态一致性检查点实现的,当有故障产生时,应用服务会重启后,再重新加载上一次成功备份的状态检查点信息。结合可重放的数据源,该特性可保证精确一次(exactly-once)的状态一致性。
- 高效的检查点: 如果一个应用要维护一个TB级的状态信息,对此应用的状态建立检查点服务的资源开销是很高的,为了减小因检查点服务对应用的延迟性(SLAs服务等级协议)的影响,Flink采用异步及增量的方式构建检查点服务。
- 端到端的精确一次: Flink 为某些特定的存储支持了事务型输出的功能,及时在发生故障的情况下,也能够保证精确一次的输出。
- 集成多种集群管理服务: Flink已与多种集群管理服务紧密集成,如 Hadoop YARN, Mesos, 以及 Kubernetes。当集群中某个流程任务失败后,一个新的流程服务会自动启动并替代它继续执行。
- 内置高可用服务: Flink内置了为解决单点故障问题的高可用性服务模块,此模块是基于Apache ZooKeeper 技术实现的,Apache ZooKeeper是一种可靠的、交互式的、分布式协调服务组件。
0x02 基于Maven构建项目
1.部署
-
安装Java环境,使用java8
-
下载maven

-
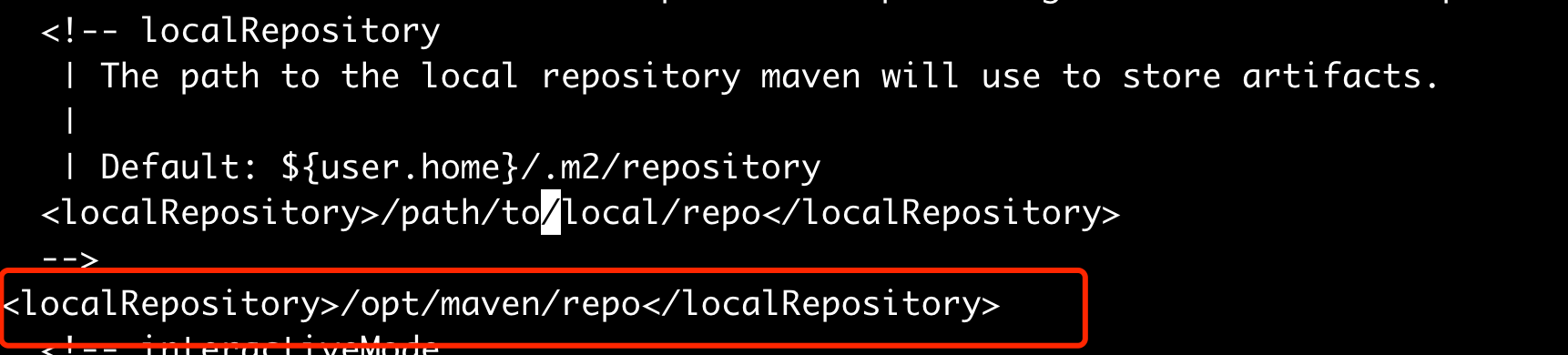
修改设置文件
conf/settings.xml
注意修改默认的库文件路径,这里修改为如下:
-
将系统添加到系统环境变量
修改.bash_profile
export MAVEN_HOME=/opt/apache-maven-3.8.2/
export PATH=$MAVEN_HOME/bin:$PATH
最后source ~/.bash_profile
测试是否安装成功
mvn -v

出现如图所示结果,表示安装成功
2.项目构建
- 运行如下命令
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-walkthrough-datastream-java \
-DarchetypeVersion=1.13.2 \
-DgroupId=frauddetection \
-DartifactId=frauddetection \
-Dversion=0.1 \
-Dpackage=spendreport \
-DinteractiveMode=false
DarchetypeVersion参数需要进行修改,选择我们需要使用的flink的版本。这是使用的是1.13.2版本。
然后可以根据自己的情况修改groupId、 artifactId 和 package。通过这三个参数, Maven将会创建一个名为 frauddetection的文件夹,包含了所有依赖的整个工程项目将会位于该文件夹下。
参数说明
groupId:定义当前Maven项目隶属的实际项目,例如org.sonatype.nexus,此id前半部分org.sonatype代表此项目隶属的组织或公司,后部分代表项目的名称,如果此项目多模块话开发的话就子模块可以分org.sonatype.nexus.pluginsorg.sonatype.nexus.utils等。特别注意的是groupId不应该对应项目隶属的组织或公司,也就是说groupId不能只有org.sonatype而没有nexus。
例如:我建立一个项目,此项目是此后所有项目的一个总的平台,那么groupId应该是org.limingming.projectName,projectName是平台的名称,org.limingming是代表我个人的组织,如果以我所在的浪潮集团来说的话就应该是com.inspur.loushang。
artifactId是构件ID,该元素定义实际项目中的一个Maven项目或者是子模块,如上面官方约定中所说,构建名称必须小写字母,没有其他的特殊字符,推荐使用“实际项目名称-模块名称”的方式定义,例如:spirng-mvn、spring-core等。
执行命令
第一次构建会下线很多库文件,需要等一会
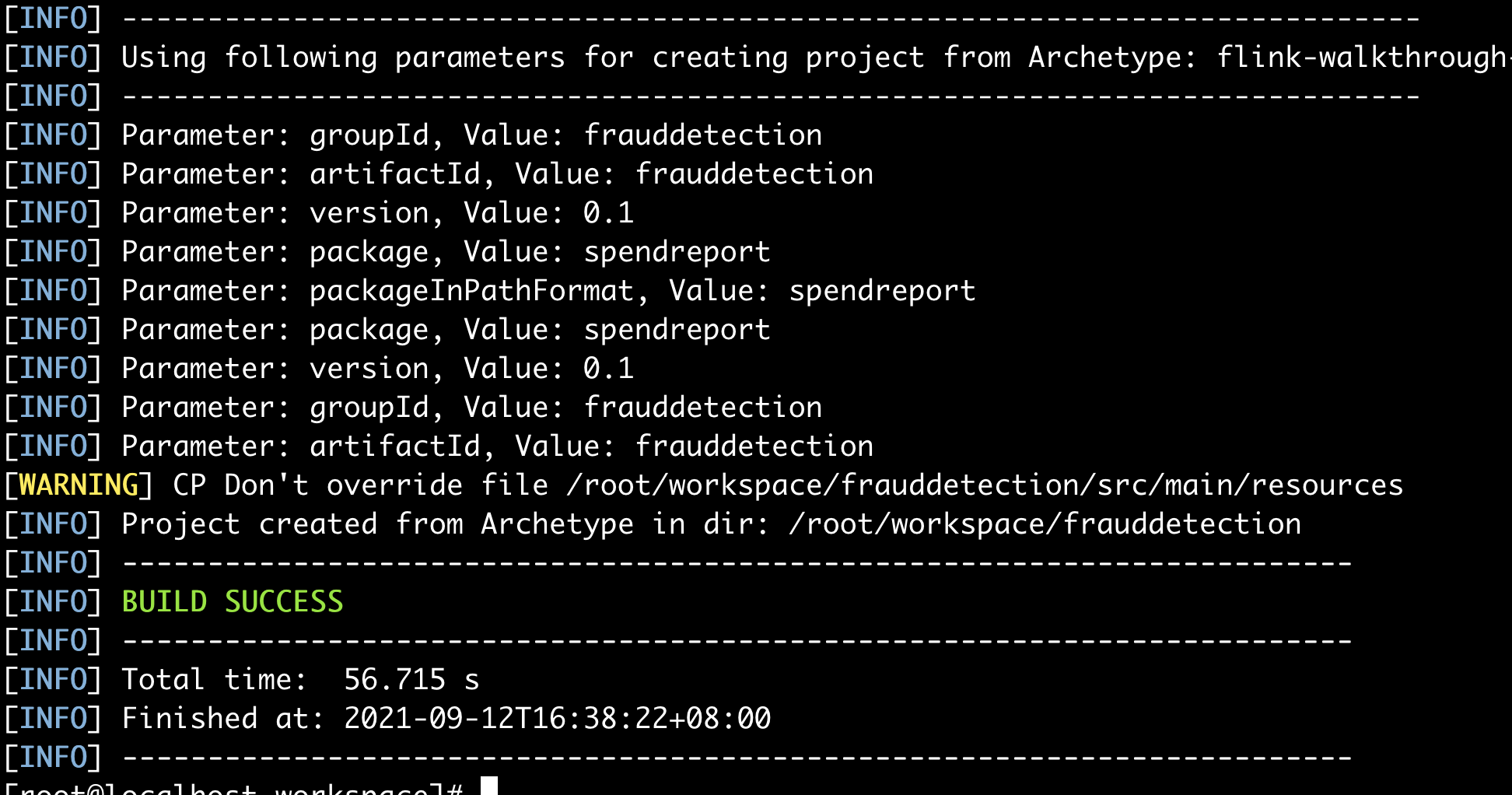
构建成功
文件结构层级说明
[root@localhost frauddetection]# tree
├── pom.xml # 以后编程中需要使用和依赖的管理文件
└── src
└── main
|—— scala # 相关scala代码(默认不自动创建)
├── java # 相关java代码
│ └── spendreport
│ ├── FraudDetectionJob.java
│ └── FraudDetector.java
└── resources # 相关的配置
└── log4j2.properties
5 directories, 4 files
源代码简析
FraudDetectionJob.java
package spendreport;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.walkthrough.common.sink.AlertSink;
import org.apache.flink.walkthrough.common.entity.Alert;
import org.apache.flink.walkthrough.common.entity.Transaction;
import org.apache.flink.walkthrough.common.source.TransactionSource;
/**
* Skeleton code for the datastream walkthrough
*/
public class FraudDetectionJob {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//数据接过来
DataStream<Transaction> transactions = env
.addSource(new TransactionSource())
.name("transactions");
//数据处理
DataStream<Alert> alerts = transactions
.keyBy(Transaction::getAccountId)
.process(new FraudDetector())
.name("fraud-detector");
//数据甩出去
alerts
.addSink(new AlertSink())
.name("send-alerts");
env.execute("Fraud Detection");
}
}
3.构建多module的Flink项目
-
新建一个project
-
选择Maven,写入GroupID和ArtifactID,创建项目
删除src目录,因为这里我们不需要主工程,只需要创建子工程
-
新建module

-
创建后的项目目录如下
u1timate@u1timate:/mnt/d/flink_code/demo-flink$ tree
.
├── demo-flink-dataset
│ ├── pom.xml
│ └── src
│ ├── main
│ │ ├── java
│ │ └── resources
│ └── test
│ └── java
├── demo-flink-datastream
│ ├── pom.xml
│ └── src
│ ├── main
│ │ ├── java
│ │ └── resources
│ └── test
│ └── java
├── demo-flink-sql
│ ├── pom.xml
│ └── src
│ ├── main
│ │ ├── java
│ │ └── resources
│ └── test
│ └── java
└── pom.xml
- 创建完成之后,查看主目录下的pom.xml
可以看到在modules项目中,已经存在我们所创建的子工程了。
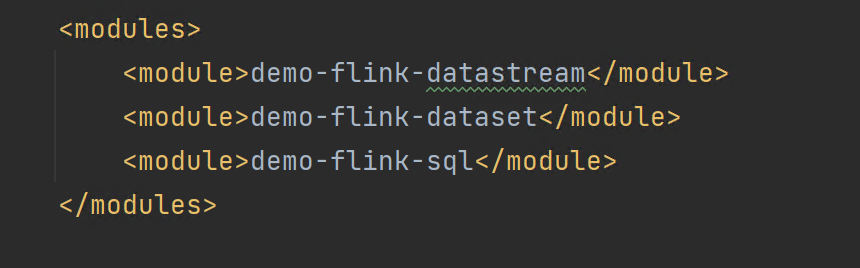
但是该配置并不是完善的,需要向其中加入一些其他的配置选项,这些配置选项可以从使用maven的mvn命令创建的项目的主工程的pom.xml文件中获取
完整版的数据如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.demo.flink</groupId>
<artifactId>demo-flink</artifactId>
<packaging>pom</packaging>
<version>1.0-SNAPSHOT</version>
<modules>
<module>demo-flink-datastream</module>
<module>demo-flink-dataset</module>
<module>demo-flink-sql</module>
</modules>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.13.2</flink.version>
<target.java.version>1.8</target.java.version>
<scala.binary.version>2.11</scala.binary.version>
<maven.compiler.source>${target.java.version}</maven.compiler.source>
<maven.compiler.target>${target.java.version}</maven.compiler.target>
<log4j.version>2.12.1</log4j.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-walkthrough-common_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- This dependency is provided, because it should not be packaged into the JAR file. -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Add logging framework, to produce console output when running in the IDE. -->
<!-- These dependencies are excluded from the application JAR by default. -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
</project>
主工程定义好好依赖后,子工程不能直接使用,需要在子工程的pom文件中单独引入这些依赖,具体示例如下配置
而在每个子工程下,也有一个pom.xml。里面有指向父工程的配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>demo-flink</artifactId>
<groupId>com.demo.flink</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>demo-flink-datastream</artifactId>
<properties>
<maven.compiler.source>16</maven.compiler.source>
<maven.compiler.target>16</maven.compiler.target>
</properties>
<!-- 引入依赖,这里会引入主工程的一些配置 -->
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
</dependency>
</dependencies>
</project>
配置完成后reload,当我们在一个子工程文件中成功引入主工程的依赖,就可以在idea中看见
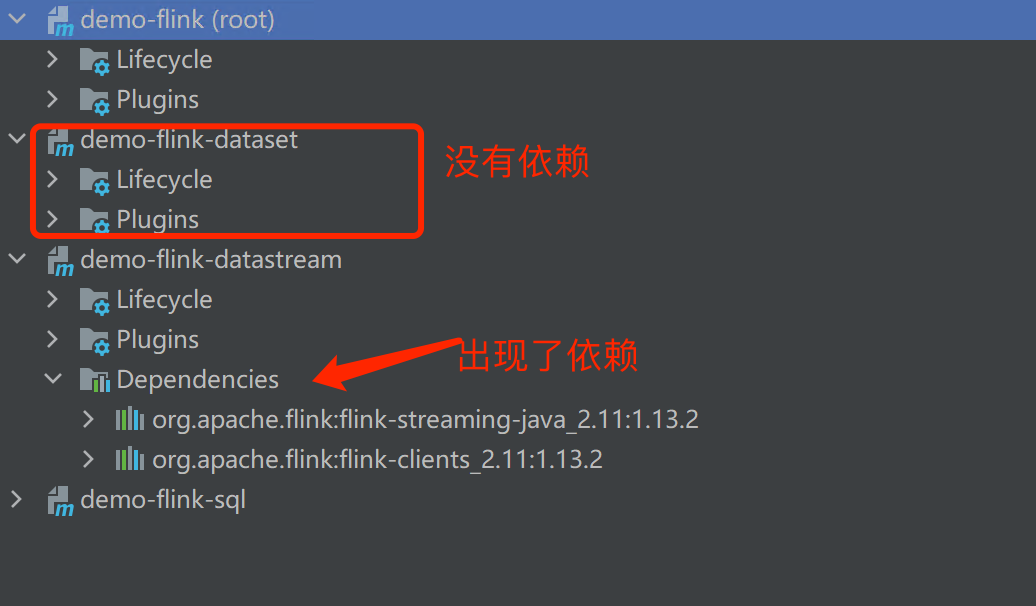
0x03. flink编程模型
- 对接数据源
- 使用引擎进行业务逻辑处理
- 输出结果,存到某地
例子
MR: InputFormat ==> Mapper => Reducer
Hive: Tables ==> SQL ==> insert
Spark: RDD/DF/DS ==> Transformation ==> Action/Oution
Flink: Source ==> Transformation ==> Slink
0x04. 案例
1 词频统计分析
- 数据来源socket
- 对数据进行统计分析
- 统计结果输出到控制台
业务逻辑
数据来源: pk,pk,pk,flink,flink
- 每行数据按照指定的分隔符进行拆分
分隔符为,
String[] words = value.split(",") - 每个单词赋值,出现的次数
(pk,1)
(pk,1)
(pk,1)
(flink,1)
(flink,1) - 相同的key分到一个任务中去进行累加操作,然后输出到控制台
(pk,3)
(flink,2)
4.1 实时处理
代码如下
package com.demo.flink.basic;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
//第一个基于flink实时处理入门案例
public class StreamingWCApp {
public static void main(String[] args) throws Exception {
//1. 获取上下文
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2. 对接数据源
DataStreamSource<String> source = env.socketTextStream("192.168.11.39",9527);
//3. 业务逻辑操作
source.flatMap(new FlatMapFunction<String, String>() { //T表示传入值,O表示传出的值
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
String[] words = s.split(",");
for(String word: words){
collector.collect(word.toLowerCase().trim());
}
}
}).filter(new FilterFunction<String>() { //过滤一些空的数据
@Override
public boolean filter(String s) throws Exception {
return StringUtils.isNotEmpty(s);
}
}).map(new MapFunction<String, Tuple2<String,Integer>>() {//传入字符串,返回一个元组('ok',2)
@Override
public Tuple2<String,Integer> map(String s) throws Exception {
return new Tuple2<>(s,1);
}
}).keyBy(0).sum(1).print(); //keyBy用来分组(被遗弃的),参数为分组字段的索引, sum表示使用索引的1的值求和
//最后执行
env.execute("StreamingWCApp");
}
}
运行
-
首先运行nc监听端口9527
nc -lk 9527

-
运行java代码
4.1 离线处理
- 首先需要创建离线数据,这里直接创建一个文件
wc.data
pk,pk,pk,flink,flink
pk,pk,flink,flink,pk
- 创建java源代码文件
BatchWCApp
package com.demo.flink.basic;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
//批处理案例
public class BatchWCApp {
public static void main(String[] args) throws Exception {
//同样获取上下文
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//读取离线数据,这里使用本地文件
DataSource dataSource = env.readTextFile("data/wc.data");
//业务处理逻辑
dataSource.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String > collector) throws Exception {
String[] words = s.split(",");
for(String word: words){
collector.collect(word.toLowerCase().trim());
}
}
}).map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String o) throws Exception {
return new Tuple2<>(o,1);
}
}).groupBy(0).sum(1).print(); //z这里替换成groupBy函数
//离线处理这里不需要执行env
}
}
输出结果
