
[toc]
0x01 环境部署
- 1 启动es docker 环境
如果要设置密码,需要开启置开启X-PACK
docker run -itd --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e "xpack.security.enabled=true" elasticsearch:7.11.1
进入该容器设置密码
docker exec -it ** bash
>>/usr/share/elasticsearch/bin/elasticsearch-setup-passwords interactive
- 2 启动kibana docker环境
docker run -itd --name kib -p 0.0.0.0:5601:5601 -e "ELASTICSEARCH_HOSTS=http://192.168.35.50:9200" docker.elastic.co/kibana/kibana:7.11.1
ELASTICSEARCH_HOSTS表示ES的地址
进入该容器设置kibana,配置连接es的用户和密码
docker exec -it ** bash
vi /usr/share/kibana/config/kibana.yml
//配置用户和密码
elasticsearch.username: "elastic"
elasticsearch.password: "sec!!!@@@"
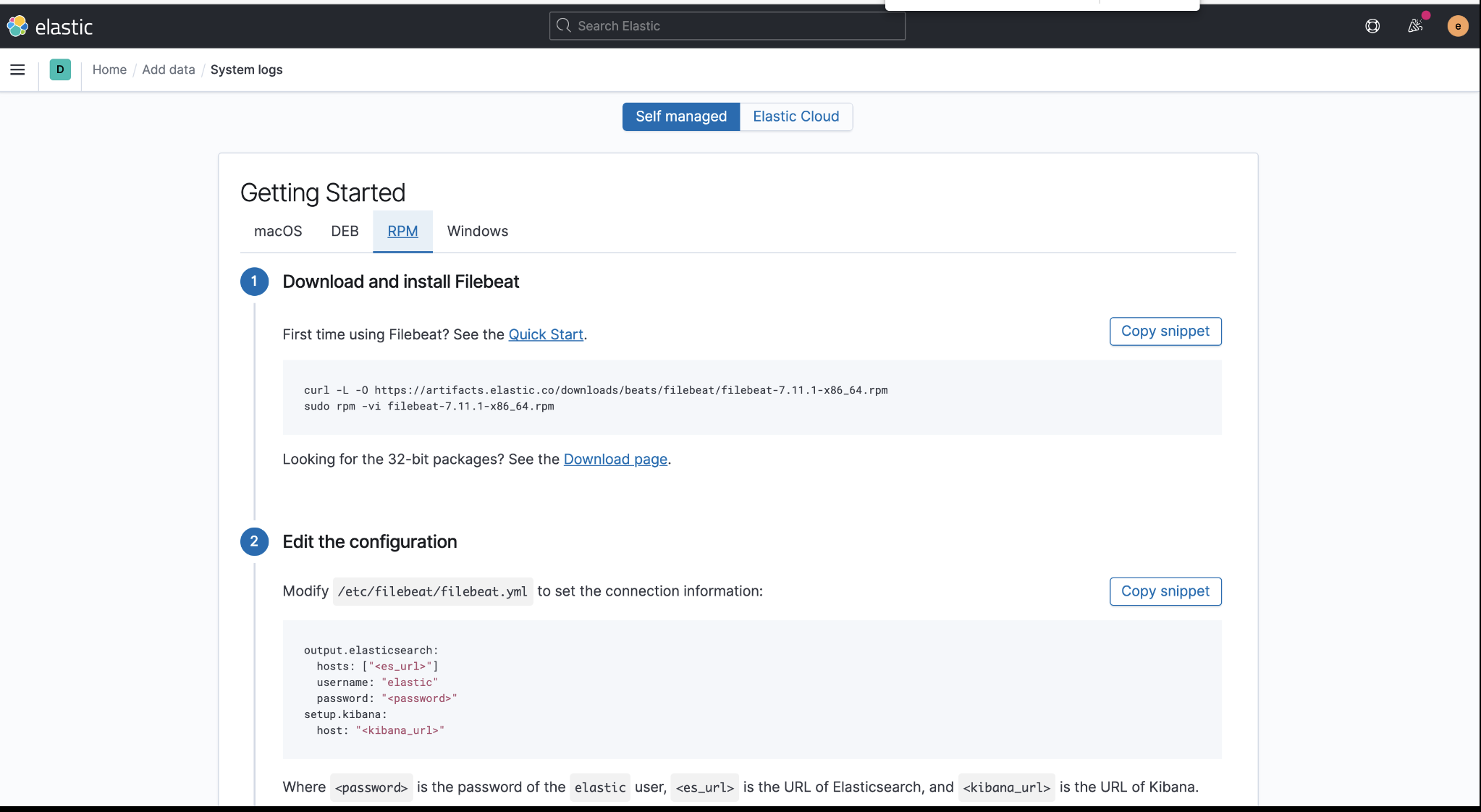
- 3 在实验系统上安装Filebeat采集相关日志发送到es中

进入logs面板后,可根据具体步骤进行安装
0x02 elastalert简单使用
elastalert是一个简单的框架,用于对来自 Elasticsearch 中的数据的异常、峰值或其他感兴趣的模式发出警报。ElastAlert 适用于所有版本的 Elasticsearch。
elastalert 通过post的告警模式,post一个告警数据包到服务端,通过服务端匹配需要告警的对象,告警的方式,最终将安全告警发出。
项目地址https://github.com/Yelp/elastalert 主分支长时间未更新
最新版本地址elastalert2 另一个开发人员基于版本1另起的一个项目进行更新,不确定是否存在bug
2.1 安装依赖
pip install -r requirements.txt
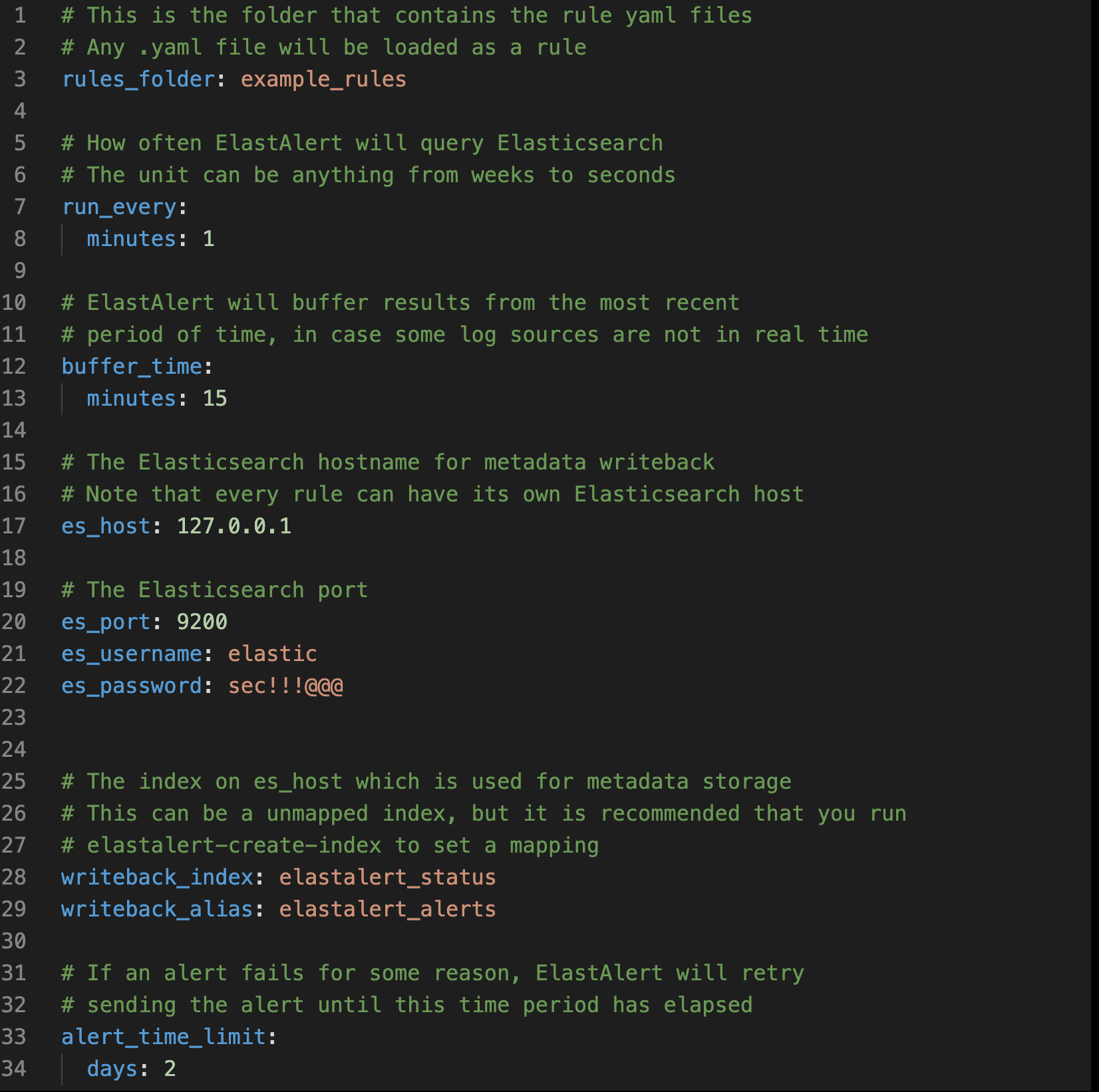
2.2 设置全局配置文件
ElastAler 有一个全局的配置文件config.yaml,它通过下面的几个配置想定义了其操作的几个方面:
buffer_time: ElastAlert 会保持一个从现在到buffertime的时间窗口并进行持续查询。通过这种方式,ElastAlert 可以查询指定时间的日志数据。这可能会具体的某一个规则所覆盖。这个选项会在use_count_query或者use_terms_query被设置为真的时候被忽略。值得注意的是,在实时查询的情况下,结果并非总是会触发基于计数的警报。
es_host: 用于存储 ElastAlert 依赖的元数据以及一些查询结果的 Elasticsearch 集群,当 ElastAlert 启动后,会查询上一次它执行的相关信息。所以,即使 ElastAlert 被停止或者重启,也绝不会漏报或重报。同时,它也是每个规则所运行的默认集群。如果配置了环境变量 ES_HOST ,这个值会被覆盖。
es_port: es_host对应的端口。如果配置了环境变量 ES_PORT,此值会被覆盖。
use_ssl: 可选项; 通过True或False控制通过TLS连接ES_HOST. 如果配置了环境变量ES_USE_SSL,这个值将会被覆盖。
verify_certs: 可选项; 通过设置True或False来控制是否校验 TLS 证书,默认为True。
es_username: 可选项; 用于连接到es_host最基本的用户名认证。如果设置了环境变量ES_USERNAME,这个值将会被覆盖。
es_password: 可选项; 用于连接到es_host最基本的密码认证。 如果设置了环境变量ES_PASSWORD,这个值将会被覆盖。
es_url_prefix: 可选项; Elasticsearch端点的网址前缀。
es_send_get_body_as: 可选项; 查询 Elasticsearch 的 http 方法 -GET,POST或者source. 默认的是GET
es_conn_timeout: 可选项; 设置连接或读取es_host数据的超时时间; 默认值为10.
rules_folder: 规则配置文件的文件夹名称,ElastAlert 会加载这个文件夹以及其子文件夹里面所有的以.yaml结尾的内容。如果配置文件的内容发生改变,ElastAlert 会根据配置各自配置文件进行加载、重载或者删除规则。
scan_subdirectories: 可选项; 配置 ElastAlert 是否获取规则文件夹中子文件夹的内容 -true或者false. 默认为true
run_every: 配置 ElastAlert 查询 Elasticsearch 的频率。 ElastAlert 会记录下每条规则对应的最后一次查询,并会智能的从该次查询停止的地方继续。该字段的格式可以是(嵌套时间单位)时分秒的形式, 比如minutes:5. ElastAlert的配置文件中将都会套用这种时间格式。
writeback_index: 监控es_host用到的 index 。
max_query_size: 单个查询所能够下载的文档数的最大值。默认是 10,000, 如果你希望接近(get near)这个数字的话,可以在规则当中使用use_count_query这个配置项。如果出现文档数量超过最大值,ElastAlert 会根据max_query_size进行滚动查询直到处理完所有的数据。
scroll_keepalive: 迭代查询保持的最大时间(以时间为单位)。 一方面避免数据量太大而占去 Elasticsearch 过多的资源,同时保证有足够的时间去处理完所有的数据。 but be mindful to allow sufficient time to finish processing all the results.
max_aggregation: 警报聚合的最大值。如果一个规则当中有聚合集,所有在一段时间内触发的警报都会一起发送出去。默认值是10000。
old_query_limit: 查询之间的最大时间,用以提供给ElasticAlert最常运行的查询处启动. 当 ElasticAlert 启动时,它会针对每条规则在 elastialert_metadata 查找最常见的查询,并于该时间点启动,除非它比 older_query_limit 大,换句话说,它将在当前启动.默认值为一个星期.
disable_rules_on_error: 若真, ElastiAlert 将在规则抛出异常(不是EAException)时禁用它. 它将上传一个追溯消息给到 elastialert_metadata,并且在 notify_email 配置的情况下,发送邮件通知.该规则将不再运行,除非 ElastiAlert 重新启动或者规则文件被修改.该值默认为True.
notify_email: 一个邮件地址或者邮件地址列表,用以通知邮件已经发送.目前,仅仅是未捕捉的异常会发送通知邮件.发件人,SMTP主机和回复标题可以通过from_addr,smtp_host和email_reply_to选项进行设置.
from_addr: 发送邮箱通知时邮件头里的地址.除非在规则配置文件中重写,否则该值将用于警报邮件.默认值为ElastAlert.
smtp_host: 发送邮件通知时使用的SMTP主机.除非在规则配置文件中重写,否则该值将用于警报邮件.默认值为 "localhost".
email_reply_to: 该值设置邮件回复标题.默认值为接收人地址.
aws_region: 在使用Amazon Elasticsearch Service时候该值使 ElastAlert 标记HTTP请求.它将使用实例角色键值标记请求.如果配置环境变量AWS_DEFAULT_REGION,该值将被重写.
boto_profile: 已弃用! 在向 Amazon Elasticserach Service 标记请求时使用的 Boto 配置文件,如果你不希望使用实例的角色键.
profile: 标记发起Amazon Elasticsearch Service的请求使用的 AWS 配置文件,如果你不希望使用实例角色键.如果配置了环境变量AWS_DEFAULT_PROFILE,该值将会别覆盖.
replace_dots_in_field_names: 若True,ElastAlert将在文档写入Elasticsearch前,把字段名称中的所有点(.)替换成下划线(_).默认值为False.Elastcserach 2.0 - 2.3 不支持带有点的字段名.
样例
config.yaml
# Elasticsearch集群配置
es_host:
es_port:
use_ssl:
verify_certs:
es_username:
es_password:
es_url_prefix:
es_conn_timeout:
# 设置检索rules和hashes的加载类
rules_loader: 'FileRulesLoader'
# 规则配置文件的文件夹的名称,仅rules_loader=FileRulesLoader时有效
rules_folder: rules
# 是否递归rules目录的子目录配置
scan_subdirectories: true
# 查询Elasticsearch的时间间隔
run_every:
minutes: 1
# 查询窗口的大小
buffer_time:
minutes: 15
# ElastAlert将存储数据的索引名称
writeback_index: elastalert
# 单次查询Elasticsearch最大文档数,默认10000
max_query_size: 10000
# 滚动浏览的最大页面数,默认0(表示不限制)
max_scrolling_count: 0
# 在滚动浏览上下文中应保持活动状态的最长时间
scroll_keepalive:
# 汇总在一起的最大警报数
max_aggregation:
# 两次查询之间的最长时间
old_query_limit:
# 禁用未捕获异常的规则,默认True
disable_rules_on_error:
# ElastAlert完成执行后会显示“禁用规则”列表
show_disabled_rules: true
# 通知邮件列表,当前只有未捕获的异常会发送通知电子邮件
notify_email:
# 警报是否包括规则中描述的元数据,默认False
add_metadata_alert: false
# 跳过无效的文件而不是退出
skip_invalid:
# 失败警报的重试窗口
alert_time_limit:
# 增强模块,与规则一起使用,将其传递给报警器之前对其进行修改或删除
match_enhancements:
- "elastalert_modules.my_enhancements.MyEnhancement"
# 匹配立刻运行增强
run_enhancements_first: true
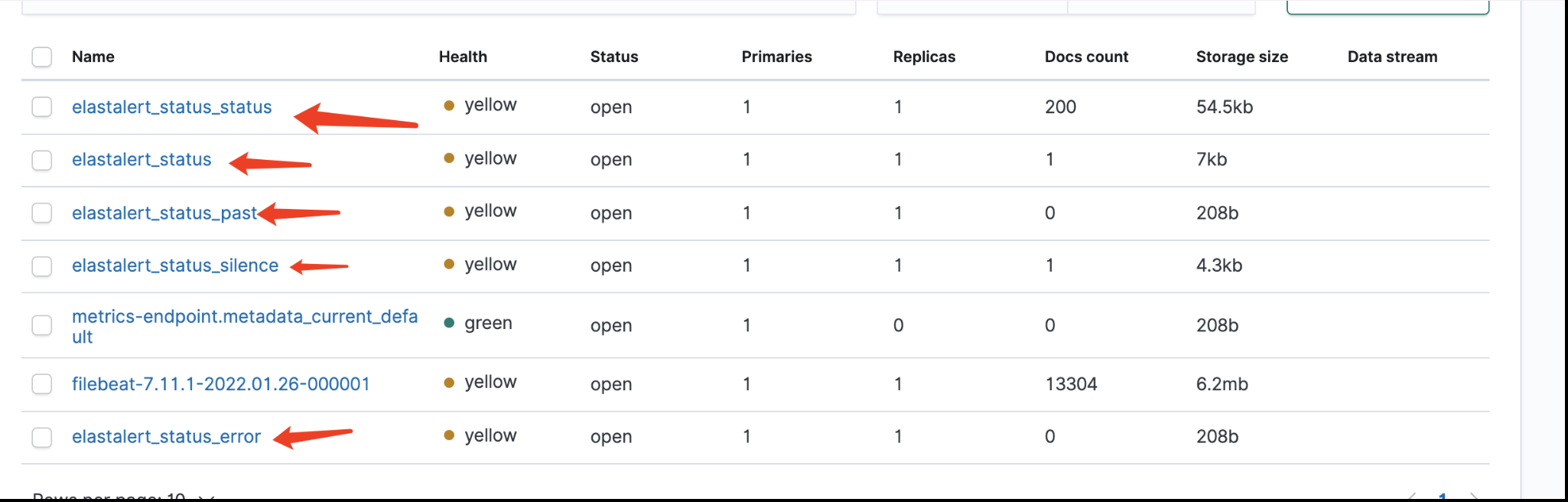
2.3 首次使用创建elastalert专用的索引(index)和映射(Mapping)
-
修改config.yaml文件
-
如果是pip安装 则直接在config.yaml目录下运行
elastalert-create-index -
脚本运行
python -m elastalert.create_index --config config.yaml使用-m原因是python3 默认导入绝对路径的缘故,参考Relative imports in Python 3 - Stack Overflow
运行完成后,脚本会自动在ES中创建索引,如下
2.4 创建规则
根据之前的config定义的规则文件夹名称,创建文件夹,这里我们使用默认的example_rules文件夹
创建基于频率的规则文件example_frequency.yaml
# Elasticsearch配置
es_host: 10.188.10.1
es_port: 9200
es_username: elastic
es_password: xxx
index: logstash-*
# Rule Type
type: 'any'
# 导入公共配置
import:
# 用于标识警报的利益相关者
owner: 'xxx'
# 用于标识警报的相对优先级
priority: 2
# 用于标识警报的类别
catagory: ''
# 规则描述
description: ''
# 设置请求里查询窗口的范围。当use_count_query或use_terms_query为true时,将忽略此值
buffer_time:
minutes: 5
# 延迟查询
query_delay:
minutes: 5
# 开启timeframe(查询开始时间=now()-timeframe)
scan_entire_timeframe: true
# 1. 查询开始时间,scan_entire_timeframe开启,use_count_query和use_terms_query未设置时有效
# 2. 规则的事件发生窗口期,如:FrequencyRule-EventWindow
timeframe:
minutes: 1
# Elasticsearch查询过滤器
filter:
- query:
query_string:
query: "level: ERROR"
# 触发报警的事件数
num_events: 5
# 传递给规则类型和警报的查询结果字段列表,默认所有字段
include:
- "username"
# 针对每个字段的前X(top_count_number)个最常用的值执行Terms查询
top_count_keys:
- "username"
# 术语的前X个最常用的值,与top_count_keys一同使用
top_count_number: 5
# 如果为true,top_count_keys中所有字段都会附加.raw
raw_count_keys: true
# 单次查询获取的最大文档数
max_query_size: 10000
# 计数查询(count api),而不下载所匹配的文档
use_count_query: false
# 聚合查询(aggregation),和query_key、doc_type、terms_size一起使用
use_terms_query: false
# use_terms_query=true时,为每个值单独计数
query_key: 'username'
# top_count_keys存在,发送警报时,多个逗号分隔,必须配合compound_query_key使用
query_key: 'service_name,username'
# 复合的查询key,必须与query_key一一对应,get_hits_terms时使用
compound_query_key:
- service_name
- username
doc_type: _doc
# 桶的最大数
terms_size: 50
# 相关事件一同报警。一个桶触发报警,其他的桶一同触发报警
attach_related: false
# 将多次匹配汇总到一个警报中,将聚合时间期内发生的所有匹配项一起发送
aggregation:
# 需要大量匹配并只需要定期报告
hours: 2
# 汇总所有警报并定期发送报警
schedule: '2 4 * * mon,fri'
# 为不同的字段值创建一个独立的聚合窗口,默认在聚合窗口期中所有事件被分组在一起
aggregation_key: 'my_data.username'
# 基于第一个事件的时间创建聚合,默认当前时间
aggregate_by_match_time: true
# 对于聚合报警,指定摘要表字段
summary_table_fields:
- my_data.username
# 忽略一段时间的重复警报,支持query_key
realert:
minutes: 10
# 使realert的值呈指数增加
exponential_realert:
hours: 1
# 是否将时间戳转换为警报中的本地时区
use_local_time: true
# 时间戳类型(iso, unix, unix_ms, custom)
timestamp_type: 'iso'
# 自定义时间戳格式
timestamp_format: '%Y-%m-%dT%H:%M:%SZ'
# 指定时间字段,默认@timestamp
timestamp_field: '@timestamp'
### Metric Aggregation Type or Percentage Match Type
# 使用run_every计算度量计算窗口大小,默认使用buffer_time
use_run_every_query_size: true
# 度量计算窗口大小,必须是buffer_time的倍数
bucket_interval:
# Alerts
alert:
- command
- debug
command: ["python3", "/opt/elastalert/weixin.py", "生产环境报警,报警:", "接口{orgPathName} 出现状态码{statusCode}频率高!","服务 IP: {directBackServer}; 服务端口:{port}"]
使用命令测试该规则是否可用
- 如果是pip安装,运行
elastalert-test-rule工具将测试您的配置文件是否成功加载并在过去的24小时内以调试模式运行它
elastalert-test-rule example_rules/example_frequency.yaml - 如果直接运行脚本
python -m elastalert.test_rule example_rules/example_frequency.yaml
成功如下
2.5 创建linux 测试日志
logger是一个shell命令接口,可以通过该接口使用Syslog的系统日志模块,还可以从命令行直接向系统日志文件写入一行信息。
logger 语法
logger [options] [messages]
**options (选项):**
-d, --udp
使用数据报(UDP)而不是使用默认的流连接(TCP)
-i, --id
逐行记录每一次logger的进程ID
-f, --file file_name
记录特定的文件
-h, --help
显示帮助文本并退出
-n, --server
写入指定的远程syslog服务器,使用UDP代替内装式syslog的例程
-P, --port port_num
使用指定的UDP端口。默认的端口号是514
-p, --priority priority_level
指定输入消息的优先级,优先级可以是数字或者指定为 "facility.level" 的格式。比如:"-p local3.info " local3 这个设备的消息级别为info。默认级别是 "user.notice"
-s, --stderr
输出标准错误到系统日志。
-t, --tag tag
指定标记记录
-u, --socket socket
写入指定的socket,而不是到内置系统日志例程。
-V, --version
现实版本信息并退出
**messages:**写入log文件的内容消息,可以与-f配合使用。
logger 以0退出表示成功,大于0表示失败。
详细参考logger(1) — Linux manual page
这里我们写入能触发alert规则的日志
sudo logger -t JUSTME this is message 1
2.6 启动测试规则
对于使用PIP命令安装的直接使用如下命令
elastalert --verbose --rule example_frequency.yaml
使用脚本直接运行
python3 -m elastalert.elastalert --verbose --rule example_frequency.yaml
如果在一分钟内有三次 process.name 信息有 JUSTME 字样,那么我们就会在我们文件~/Downloads/elastalert-elastalert025/elasticalert_modules/alerts.log中查看。
结果
{
"agent": {
"hostname": "cmustard-VirtualBox",
"name": "cmustard-VirtualBox",
"id": "92469132-3f23-408c-abc3-f367994b3b24",
"ephemeral_id": "571e8fd6-bff7-4f1f-ac8c-62e963531d56",
"type": "filebeat",
"version": "7.11.1"
},
"process": {
"name": "JUSTME"
},
"log": {
"file": {
"path": "/var/log/syslog"
},
"offset": 781432
},
"fileset": {
"name": "syslog"
},
"message": "this is message 7",
"input": {
"type": "log"
},
"@timestamp": "2022-02-09T17:55:01+08:00",
"system": {
"syslog": {}
},
"ecs": {
"version": "1.7.0"
},
"related": {
"hosts": [
"cmustard-VirtualBox"
]
},
"service": {
"type": "system"
},
"host": {
"hostname": "cmustard-VirtualBox",
"os": {
"kernel": "5.13.0-27-generic",
"codename": "focal",
"name": "Ubuntu",
"family": "debian",
"version": "20.04.2 LTS (Focal Fossa)",
"platform": "ubuntu"
},
"containerized": false,
"ip": [
"192.168.18.210",
"fe80::76a8:4094:cfb1:4248",
"172.18.0.1",
"172.17.0.1"
],
"name": "cmustard-VirtualBox",
"id": "4260569be8d44ce2bbd72a243549161f",
"mac": [
"08:00:27:ec:0b:84",
"02:42:63:87:26:44",
"02:42:78:cc:5f:a6"
],
"architecture": "x86_64"
},
"event": {
"ingested": "2022-02-09T09:55:07.760856100Z",
"timezone": "+08:00",
"kind": "event",
"module": "system",
"dataset": "system.syslog"
},
"_id": "UDjo3X4BU30akiAhew5x",
"_index": "filebeat-7.11.1-2022.01.26-000001",
"_type": "_doc",
"num_hits": 17, //命中规则的日志数量
"num_matches": 1, //匹配规则后触发的告警数量,这并不一定意味着已触发警报。
"rule_name": "any_rule",
"rule_level": "medium"
}
0x03 elastalert规则类型
以下的规则类型均使用以下文档样本作触发告警:
doc = {
"@timestamp": get_now(),
"codec": "nodejs",
"tags": "31",
"level": "high",
"server": "nginx",
"status": "anystatus",
"message": ">>> [ xxx ]: valid id error ."
}
3.1 any类型
说明:任何规则都会匹配, 查询返回的每个命中将生成一个警报。
规则:当匹配status字段为anystatus,触发告警。
# rule名称
name: any_rule
# 规则类型
type: any
# 监控索引
index: testalert
# 监控时间1分钟内
timeframe:
minutes: 1
# Elastic DSL语法
filter:
- term:
status: "anystatus"
# 告警方式
alert: post
# 服务端接口
http_post_url: "http://localhost:8088/alertapi"
http_post_static_payload:
# 添加到post包中的数据,规则名称
rule_name: any_rule
# 添加到post包中的数据,告警级别
rule_level: medium
3.2 blacklist类型
说明:黑名单规则将检查黑名单中的某个字段,如果它在黑名单中则匹配。
规则:当字段status匹配到关键字hacker、huahua,触发告警
name: blacklist_rule
type: blacklist
index: testalert
timeframe:
minutes: 1
compare_key: status
blacklist:
- "hacker"
- "huahua"
alert: post
http_post_url: "http://localhost:8088/alertapi"
http_post_static_payload:
rule_name: blacklist_rule
rule_level: medium
3.3 whitelist类型
说明:与黑名单类似,此规则将某个字段与白名单进行比较,如果列表中不包含该字词,则匹配。
3.4 change类型
说明:此规则将监视某个字段,并在该字段更改时进行匹配,该领域必须相对于最后一个事件发生相同的变化。
规则:当server字段值相同,codec字段值不同时,触发告警。
name: change_rule
type: change
index: testalert
timeframe:
minutes: 1
compare_key: codec
ignore_null: true
query_key: server
alert: post
http_post_url: "http://localhost:8088/alertapi"
http_post_static_payload:
rule_name: change_rule
rule_level: medium
字段解析:
compare_key:与上一条记录做对比的字段
query_key:与上一条记录相同的字段
ignore_null:忽略记录不存在compare_key字段的情况
3.5 frequency类型
说明:当给定时间范围内至少有一定数量的事件时,此规则匹配。 这可以按照每个query_key来计数。
规则:当字段status匹配到关键字frequency超过3次(包括3次),触发告警
name: frequency_rule
type: frequency
index: testalert
num_events: 3
timeframe:
minutes: 1
filter:
- term:
status: "frequency"
alert: post
http_post_url: "http://localhost:8088/alertapi"
http_post_static_payload:
rule_name: frequency_rule
rule_level: medium
3.6 spike类型
说明:当某个时间段内的事件量比上一个时间段的spike_height时间大或小时,这个规则是匹配的。它使用两个滑动窗口来比较事件的当前和参考频率。 我们将这两个窗口称为“参考”和“当前”。
规则:当前窗口数据量为3,当前窗口超过参考窗口数据量次数1次,触发告警。
name: spike_rule
type: spike
index: testalert
timeframe:
minutes: 1
threshold_cur: 3
spike_height: 1
spike_type: "up"
filter:
- term:
status: "spike"
alert: post
http_post_url: "http://localhost:8088/alertapi"
http_post_static_payload:
rule_name: spike_rule
rule_level: medium
字段解析:
threshold_cur:当前窗口初始值
spike_height:当前窗口数据量连续比参考窗口数据量高(/低)的次数
spike_type:高或低
3.7 cardinality类型
说明:当一个时间范围内的特定字段的唯一值的总数高于或低于阈值时,该规则匹配
规则:1分钟内,level的唯一数量超过2个(不包括2个),触发告警。
name: test_rule
index: testalert
type: cardinality
timeframe:
minutes: 1
cardinality_field: level
max_cardinality: 2
alert: post
http_post_url: "http://localhost:8088/api/alert"
http_post_static_payload:
rule_name: test_rule
rule_level: medium
3.8 percentage match类型
说明:当计算窗口内的匹配桶中的文档的百分比高于或低于阈值时,此规则匹配。计算窗口默认为buffer_time。
规则:当level字段未high,时间窗口内日志量高于前一个时间窗口95%,触发告警。
name: percentage_match_rule
type: percentage_match
index: testalert
# description: "test description"
buffer_time:
minutes: 1
max_percentage: 95
match_bucket_filter:
- term:
level: high
doc_type: mydata
alert: post
http_post_url: "http://localhost:8088/alertapi"
http_post_static_payload:
rule_name: percentage_match_rule
rule_level: medium
3.9 flatline
当threshold一段时间内事件总数低于给定时间时,此规则匹配
- threshold: 不触发报警的最小事件数
- timeframe:可选参数:
- use_count_query: 如果为true,elastalert将使用count api轮询elasticsearch,而不是下载所有匹配的文档。如果只关心数据而不关心实际数据。
3.10 new_term
字段的值与30天前的数据比较是否是新出现的,如比较后是新值,则触发报警。
- new_term: 此规则匹配新值出现在以前从未见过的字段中。当 ElastAlert启动时,它将使用聚合查询来收集字段列表的所有已知术语。
- fields: 要监视的字段
3.11 增加新的规则类型
内置的规则类型在文件elastalert/ruletypes.py中,都是RuleType的子类。
自定义实现规则类型需要按照如下标准编写
class AwesomeNewRule(RuleType):
# ...
def add_data(self, data):
# ...
def get_match_str(self, match):
# ...
def garbage_collect(self, timestamp):
# ...
完成开发后,可以通过在规则文件中导入该模块,完成应用,如下
type: "elastalert_modules.my_rules.AwesomeRule"
注意文件的层级
elastalert
-- __init__.py
-- ....
elasticalert_modules
-- __init__.py
-- my_alert.py
example_rules
-- example_frequency.yaml
在example_rules文件夹根目录下运行
python3 -m elastalert.elastalert --verbose --rule example_frequency.yaml
基础变量简介
self.rules:这个字典是从规则配置文件中加载的。 如果有时间框架配置选项,则在加载规则时,它将自动转换为 datetime.timedelta 对象。self.matches:这是存放ElastAlert进行规则检测相关数据的变量。 任何与匹配相关的信息(通常来自 Elasticsearch 中的字段)都应放入字典对象并添加到 self.matches。 ElastAlert将定期弹出项目并根据这些对象发送警报。 建议您使用 self.add_match(match) 添加匹配项。 除了附加到 self.matches 之外,self.add_match 还会将 datetime @timestamp 转换回 ISO8601 时间戳。self.required_options:这是配置文件中必须存在的一组选项。 在尝试实例化RuleType之前,ElastAlert将确保所有这些字段都存在。
样例实现
import dateutil.parser
from elastalert.ruletypes import RuleType
# elastalert.util includes useful utility functions
# such as converting from timestamp to datetime obj
from elastalert.util import ts_to_dt
class AwesomeRule(RuleType):
# 确保规则配置文件中包含集合中声明的字段,否则alert会抛异常
required_options = set(['time_start', 'time_end', 'usernames'])
# 每次查询 Elasticsearch 时都会调用 add_data。
# data 是来自 Elasticsearch 的文档列表,按时间戳排序,
# 需要在规则配置中使用“include”指定的我们所需要的字段,否则data中不会存在该字段数据
def add_data(self, data):
for document in data:
# To access config options, use self.rules
if document['username'] in self.rules['usernames']:
# Convert the timestamp to a time object
login_time = document['@timestamp'].time()
# Convert time_start and time_end to time objects
time_start = dateutil.parser.parse(self.rules['time_start']).time()
time_end = dateutil.parser.parse(self.rules['time_end']).time()
# If the time falls between start and end
if login_time > time_start and login_time < time_end:
# 使用 self.add_match函数增加一个成功匹配的文档
self.add_match(document)
# alert将调用此函数以获取有关警报匹配的人类可读字符串。
# 需要返回字符串,该字符串提供有关匹配的一些信息(告警信息)。
# match包含了es文档数据
def get_match_str(self, match):
return "%s logged in between %s and %s" % (match['username'], self.rules['time_start'], self.rules['time_end'])
# garbage_collect is called indicating that ElastAlert has already been run up to timestamp
# garbage_collect函数别调用表示elastalert已经运行超时了
# 可以通过该函数判断从es中查询是结果是否为空,因为add_data函数在es返回空列表的情况下不会被调用
def garbage_collect(self, timestamp):
pass
与该自定义规则类型相对应的规则如下
name: "Example login rule"
es_host: elasticsearch.example.com
es_port: 14900
type: "elastalert_modules.my_rules.AwesomeRule"
# Alert if admin, userXYZ or foobaz log in between 8 PM and midnight
time_start: "20:00"
time_end: "24:00"
usernames:
- "admin"
- "userXYZ"
- "foobaz"
# We require the username field from documents
include:
- "username"
alert:
- debug
告警详细格式为
Example login rule
userXYZ logged in between 20:00 and 24:00
@timestamp: 2015-03-02T22:23:24Z
username: userXYZ
0x04 自定义告警方式
elastalert内置的告警方式在国内不太适用,它内置的告警方式如telegram,googlechat等, 因此可能需要我们根据实际需求自定义告警方式。
4.1 基础变量简介
self.required_options:这是一个必须在规则文件中存在配置选项的集合。如果缺少任何选项,ElastAlert将会抛出异常, 且不会实例化该告警。
self.rule:包含规则文件中所有配置的字典。可以通过访问该变量获取某个配置具体配置数据
self.pipeline:这是一个字典对象,用于在alert之间传输信息。触发alert时,将创建一个新的空管道对象,每个alerter都可以从中添加或接收信息。请注意,alerter按照它们在规则文件中定义的顺序被调用。例如,JIRA alert会将其 ticket number 添加到管道中,如果该ticket存在于管道中,电子邮件alerter将添加该ticket。
4.2样例
from elastalert.alerts import Alerter, BasicMatchString
class AwesomeNewAlerter(Alerter):
# 规则文件中必须包含该配置
required_options = set(['output_file_path'])
# Alert is called
def alert(self, matches):
# Matches 是包含规则匹配项的列表。
# 当警报设置了聚合选项时,它包含多个匹配项
for match in matches:
# Config options can be accessed with self.rule
with open(self.rule['output_file_path'], "a") as output_file:
# basic_match_string will transform the match into the default
# human readable string format
match_string = str(BasicMatchString(self.rule, match))
output_file.write(match_string)
# get_info 在发送警报后调用,发送警报后,elastalert会将警报数据写入ES,该函数就可以获取写回ES数据中alert_info字段的具体数据
# 该函数应该返回与警报功能相关的信息字典
def get_info(self):
return {'type': 'Awesome Alerter',
'output_file': self.rule['output_file_path']}
4.3 规则文件配置
alert: "elastalert_modules.my_alerts.AwesomeNewAlerter"
output_file_path: "/tmp/alerts.log"
0x05 规则过滤器
规则中使用的filter是 Elasticsearch 查询 DSL 语法的一部分。过滤器部分完全按如下方式传递给 Elasticsearch:
filter:
and:
filters:
- [filters from rule.yaml] //这里是来自elastalert配置文件中filter数据
5.1通用过滤器
query_string
可用于对多个字段进行部分或完全匹配
filter:
- query:
query_string:
query: "username: bob"
- query:
query_string:
query: "_type: login_logs"
- query:
query_string:
query: "field: value OR otherfield: othervalue"
- query:
query_string:
query: "this: that AND these: those"
都是且的关系
term
term类型允许精确的字段匹配
filter:
- term:
name_field: "bob"
- term:
_type: "login_logs"
terms
terms类型允许轻松组合多个term过滤器
filter:
- terms:
field: ["value1", "value2"] # value1 OR value2
或者
filter:
- terms:
fieldX: ["value1", "value2"]
fieldY: ["something", "something_else"]
fieldZ: ["foo", "bar", "baz"]
wildcard
支持通配符的模糊检索
filter:
- query:
wildcard:
field: "foo*bar"
range
filter:
- range:
status_code:
from: 500
to: 599
0x05 增强功能
Enhancements是允许您在发送警报之前修改匹配项的模块。它们应该是 BaseEnhancement的子类,可以在 elastalert/enhancements.py 中找到。可以使用 match_enhancements 选项将它们添加到规则中:
match_enhancements:
- module.file.MyEnhancement
样例
- 创建增加功能的包
$ mkdir elastalert_modules
$ cd elastalert_modules
$ touch __init__.py
- 创建相关类
from elastalert.enhancements import BaseEnhancement
class MyEnhancement(BaseEnhancement):
# The enhancement is run against every match
# The match is passed to the process function where it can be modified in any way
# ElastAlert will do this for each enhancement linked to a rule
def process(self, match):
if 'domain' in match:
url = "http://who.is/whois/%s" % (match['domain'])
match['domain_whois_link'] = url
- 最后修改规则文件
match_enhancements:
- "elastalert_modules.my_enhancements.MyEnhancement"
0x06 规则管理
我们需要添加规则,先添加到数据库中,然后在规则目录下,创建对应的yaml规则文件即可。
同步方式
- 可通过定时获取数据库中规则文件,然后比对规则目录下规则文件,确定当前规则是否一致
- 通过发布订阅或者规则下发的方式通知规则管理客户端去数据库取新的规则